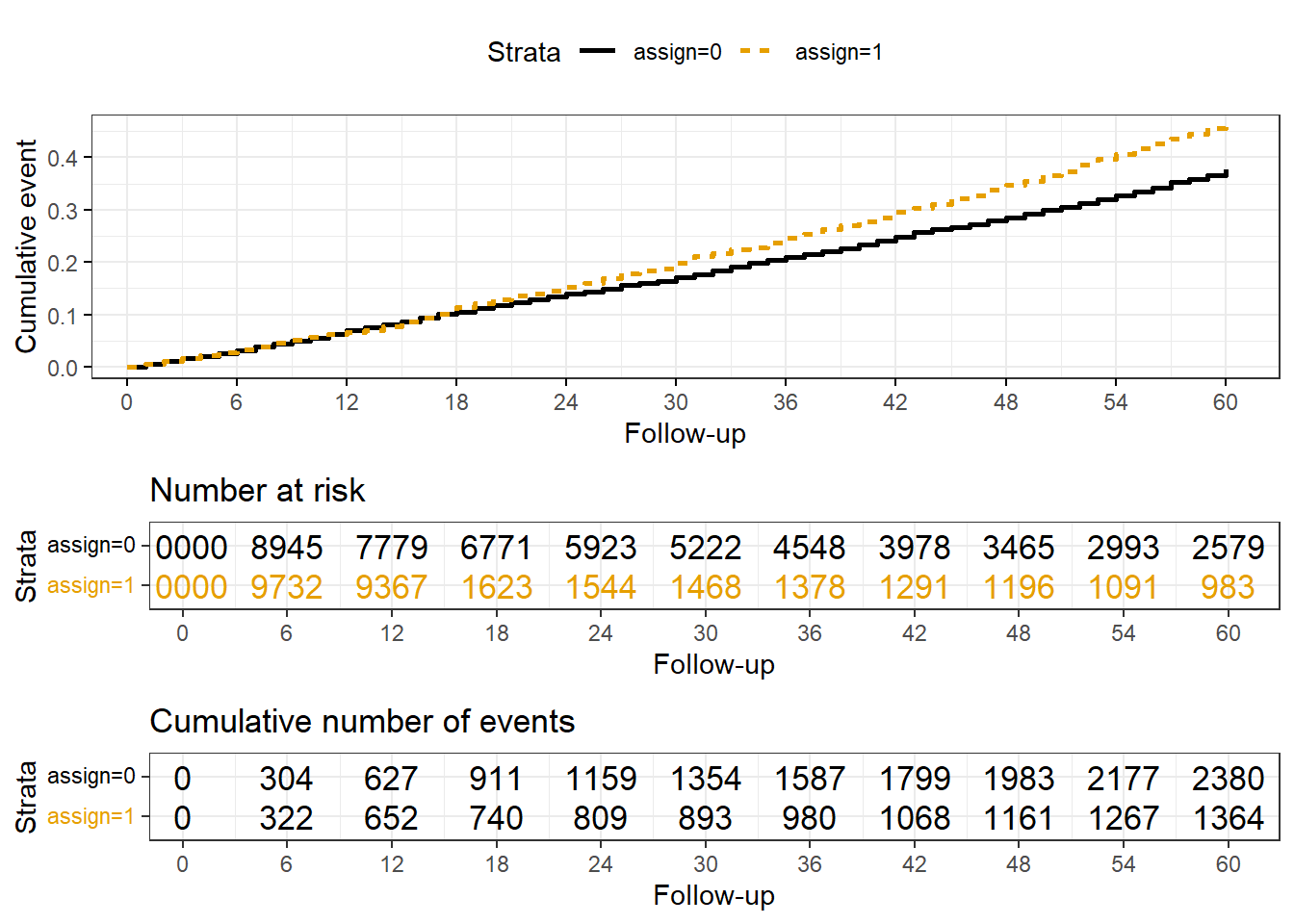
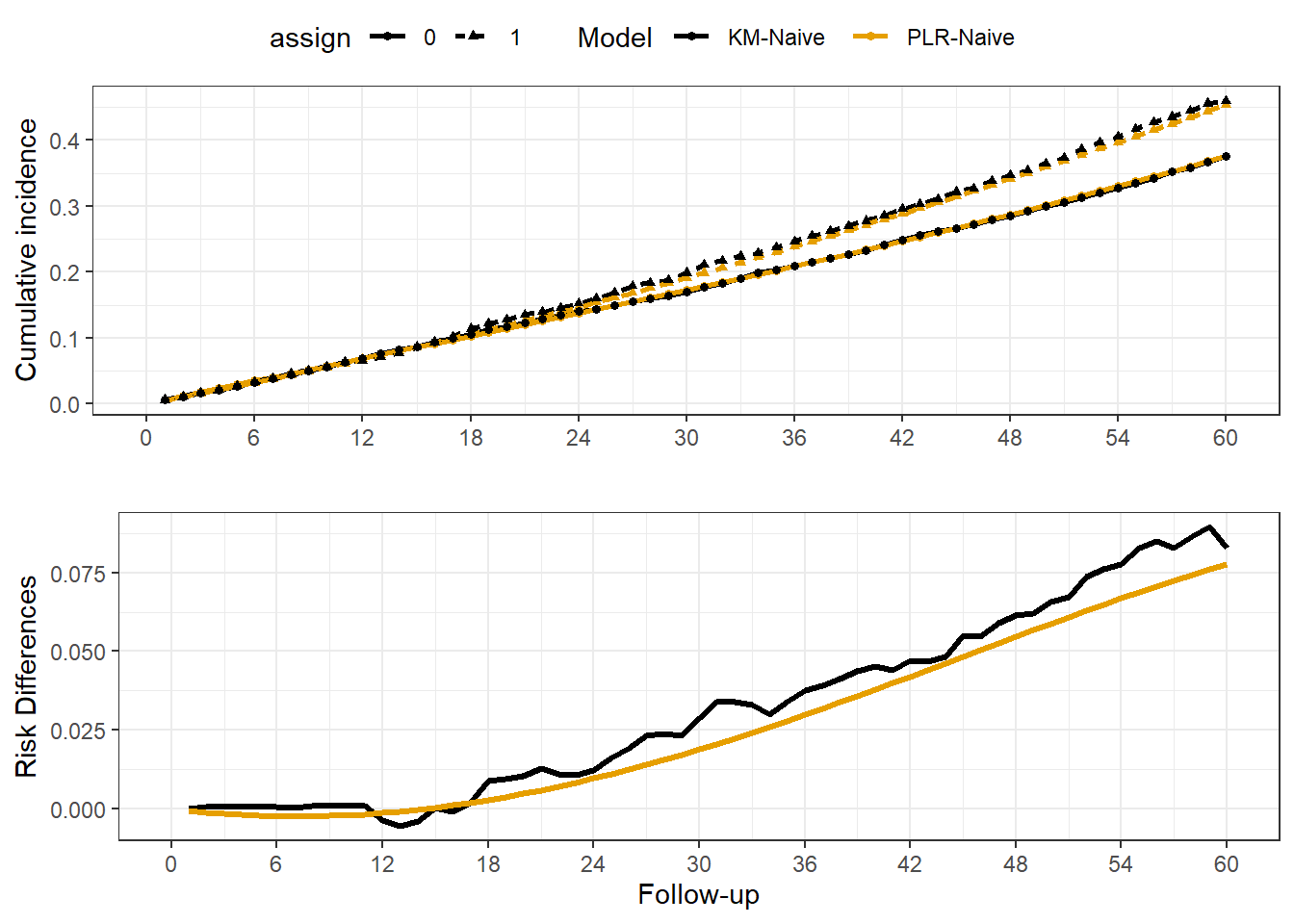
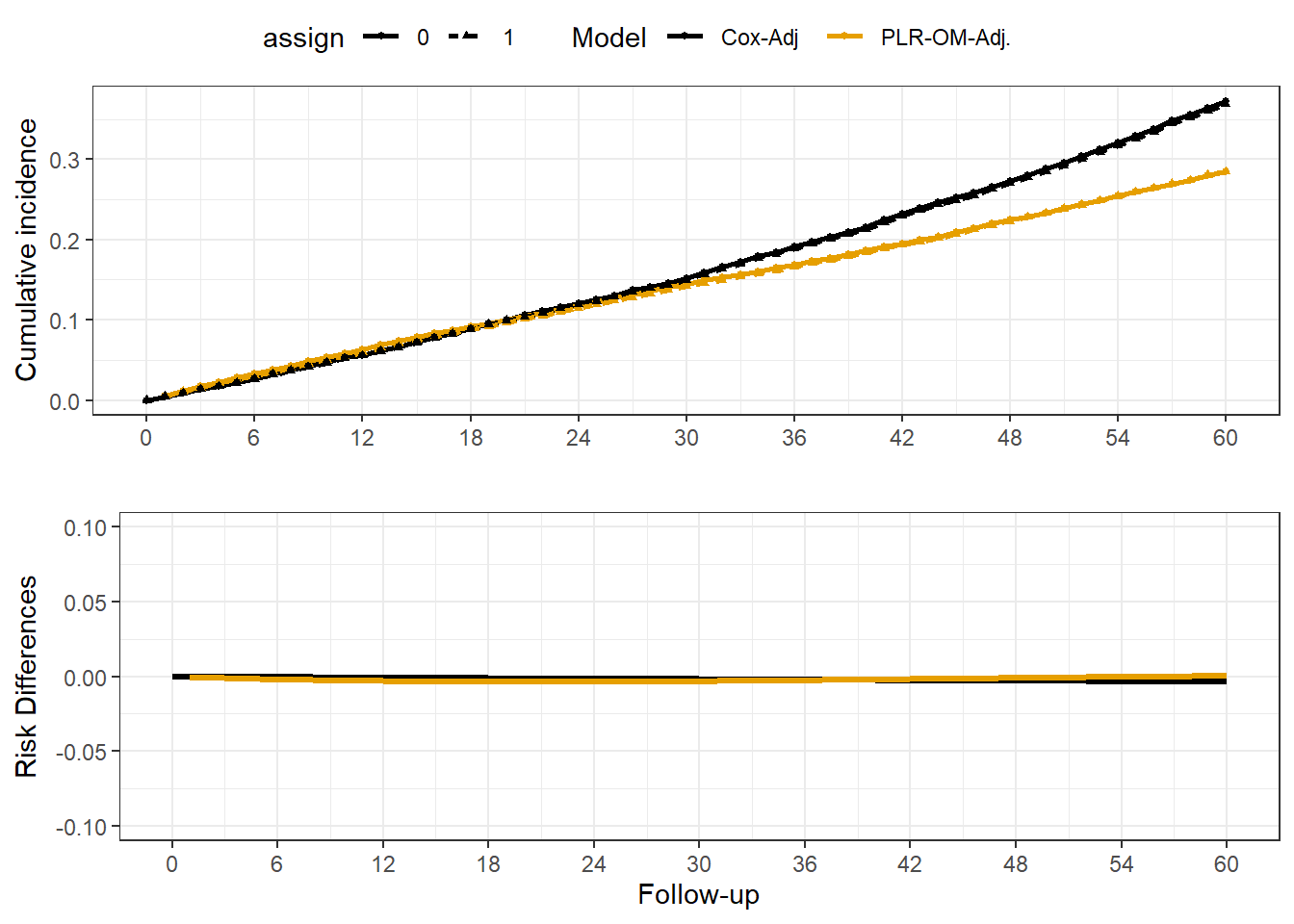
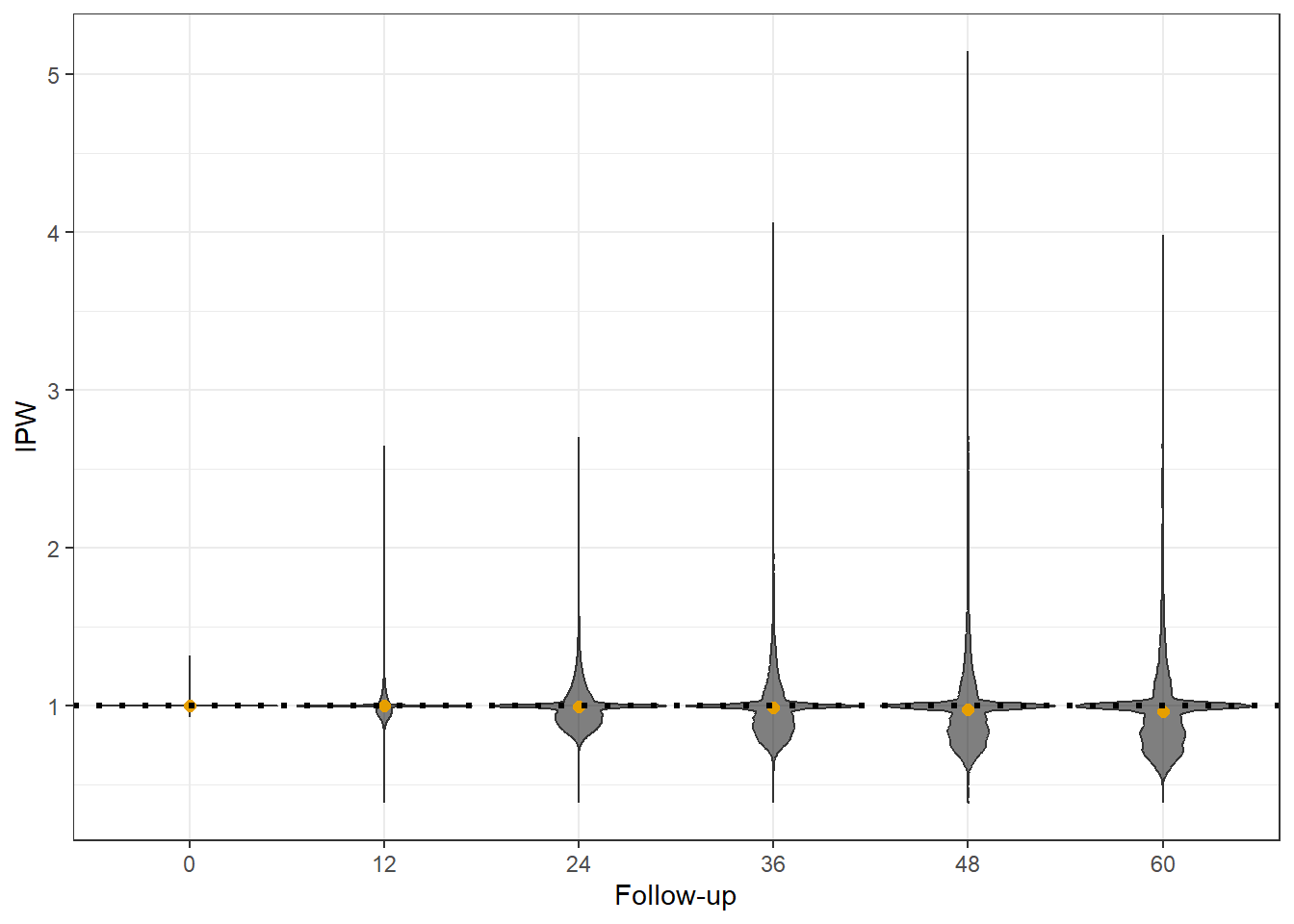
Rows: 20,000
Columns: 10
$ id <int> 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10…
$ assign <dbl> 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, …
$ t_treat <dbl> Inf, Inf, 20, 20, Inf, Inf, 22, 22, 16, 16, Inf, Inf, 24, 24…
$ t_outcome <dbl> 46, 46, Inf, Inf, 77, 77, Inf, Inf, 73, 73, 87, 87, 67, 67, …
$ t_censor <dbl> Inf, 12, 20, 12, Inf, 12, 22, 12, 16, 12, Inf, 12, 24, 12, 1…
$ time <dbl> 46, 12, 20, 12, 60, 12, 22, 12, 16, 12, 60, 12, 24, 12, 14, …
$ event <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ X <dbl> -0.7311102, -0.7311102, -2.5249386, -2.5249386, -0.6470915, …
$ female <dbl> 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ age <dbl> 70.0, 70.0, 76.3, 76.3, 74.2, 74.2, 83.9, 83.9, 76.2, 76.2, …